Introduction
The algorithm I describe in this post is something I came up with for Fast Food, the game I am working on during my Senior year at DigiPen Bilbao.
The main mechanic of the game is fast movement along rails, we decided to use splines to represent the rails because it provided a versatile way to edit the levels and a strong base for the implementation of the movement.
The Spline Component of UE4 gave us most of the functionality we needed. Still, we decided not to use the conventional UE4 collision detection system for splines. The splines are visually represented using Spline Mesh Components, this means that collision is handled in a per-object basis.

On the other hand, we don’t always want to know when the player collides with a spline, but also the distance to the spline. This led to the final decision of using distance (point to spline) for all our computations. If the distance is very small, we assume the object is colliding with the spline.
The Problem
Here is a visual representation of our problem:

It’s important to mention that we cannot find the exact nearest point, but we can approximate the solution. One mathematical approach would be to use the Newton–Raphson method, I won’t discuss or consider this mathematical solution, in part, because it has some corner cases where the algorithm misbehaves.
A spline is represented with a series of control points, to compute the parts in-between control points we need to sample the curve. We don’t have direct information about all points in the spline.
Sampling the curve implies searching in one or more look up tables before we can apply the mathematical equations. Which means, sampling the curve is not trivial, the less times we do it, the better.
Why sampling the curve means looking in some tables? Isn’t it just a mathematical formula?
Yes, the curve representation is just a mathematical formula. But, as we want to move at constant speed along the curve, the mathematical formula doesn’t provide this functionality by default and therefore some computations are needed before applying the mathematical formula. A common implementation of spline curves precompute some data and fill some look up tables.
You can see an example of this in my Advanced Animation project under the Motion Along a Curve title.
Brute force Solution
As usual, the brute force solution is the easiest one to implement. In this case the solution consists on sampling points on the curve separated by a small distance. For example, if the curve length is 100, we could sample a point every 2 units and perform 50 tests; or every 0.5 units, to get a more precise solution, having to check 200 points. This method escalates very poorly.
Here you can see an example of a spline using the brute force approach performing 184 checks:

The precision of this approach is constant but needs a lot of points to get it accurate. In the video you can see, represented as a white sphere, the nearest point on the spline from the cone. (The blue numbers on the left represent the number of checks been made for the last few frames, top is current frame)
Improved Solution – Using Space Partitioning
WARNING: This solution is not a silver bullet, it was developed having in mind the needs of the gameplay programming team. We needed to perform two types of tests depending on the situation: check if the player is more or less near to a spline and whether the player is almost touching the spline (colliding with it).
Coming up with the idea
The problem we are facing is similar to the one we face in collision detection, having to perform a lot of tests. To reduce the number of tests and potentially improve performance, we avoid checking objects that are far away from each other, for this, we use space partitioning. In the spline scenario we can apply a similar approach, perform low precision tests for parts of the spline that are far away from our point.
The basic idea consists on dividing the spline in big segments, perform one check per segment. If a check determines we could be near that segment, we subdivide the segment in two and perform another check repeating the process until we have an accurate enough solution.
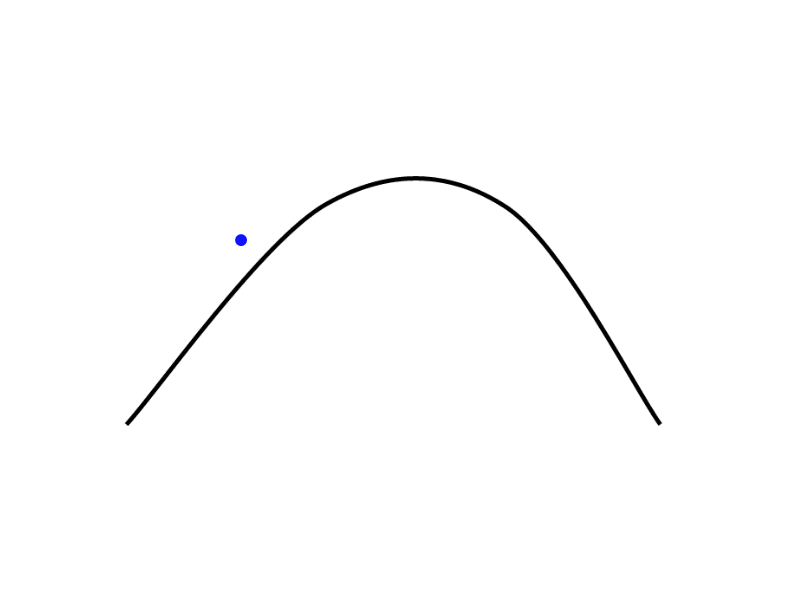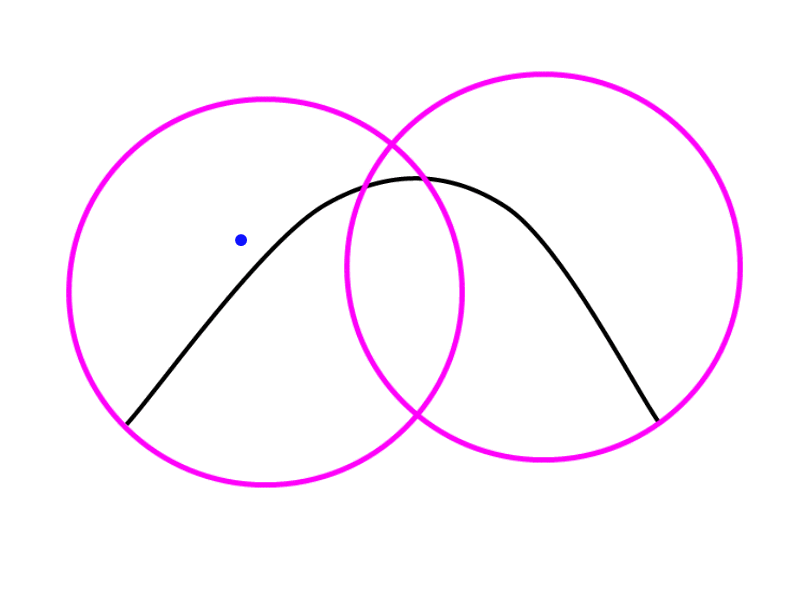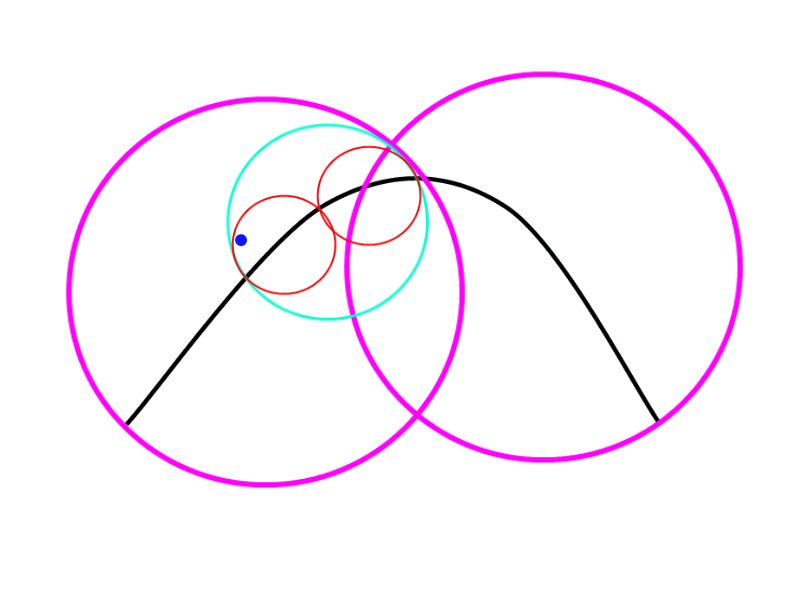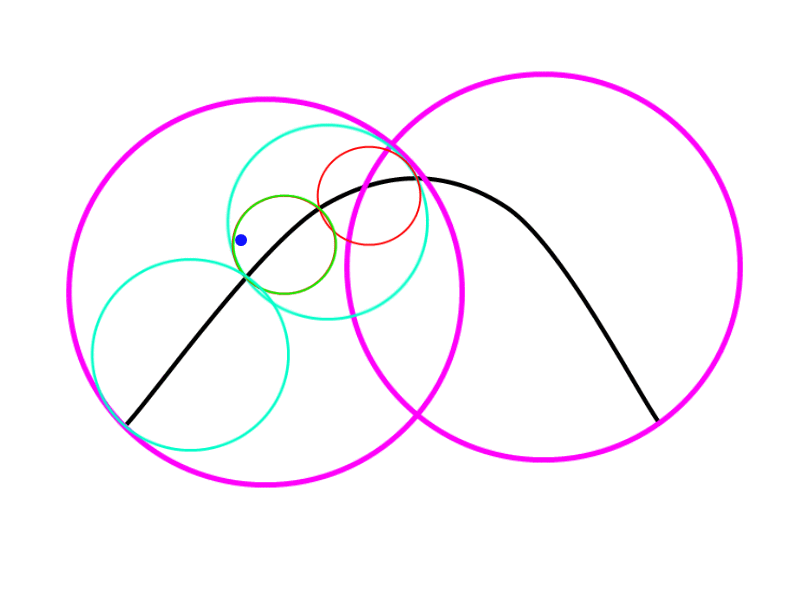
Spherical Partition

We will perform spherical space partitioning, checking whether a point inside a sphere is the cheapest test we can perform. We will create a sphere that contains each spline segment, the size of the segments is determined by the user and the best value may change between applications in order to get the best performance.
The segment must always be contained in the sphere, no matter its curvature. In order to achieve this, we have to set the center of the sphere equal to the center of the segment and the radius equal to half the segment length. Here you can see a 2D example:

Checking against the spheres

Once we have our spheres, what we have to do is check if our point is inside a sphere or not, if the point is inside: we subdivide the segment by half, generate new spheres out of the two new segments and check again recursively if the point inside this spheres. We repeat this operation until we determine that the point is “near enough” (latter we will determine what is “near enough”).
Fixing the last corner case
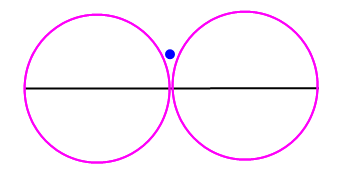
At this point, you may have realized that we still have a corner case in our algorithm. In the situation here the algorithm will say that the point is not near the spline.
To solve this problem we will add another variable to our algorithm, we will call it _input_range_distance_. This distance represents the range at which the user expects the point to be or phrasing it in another way, how precise the user wants the computations. If a gameplay programmer just wants to check if the spline is more or less near the object, it will give a big value to the _input_range_distance_, if he wants to check collision it will give a very small distance.

Now, we just need to add it to the radius of the sphere we are checking, this will increase the size of the sphere enough to make the corner case above banish. In case after increasing the size of the spheres the point doesn’t fall inside it, the algorithm returns false (point is not in that range) if the point is inside we subdivide the spline recursively as much as we can and return the nearest distance we find.
Pseudo code
- 1. Divide the spline in segments.
- 2. Check if the point is within segment range.
- 3. If our point in range.
- 4. If range is less than threshold
- Check if we need to update the solution (we want the point that is nearest to the spline).
- 5. Else
- 6. Divide segment in two segments.
- 7. Back to step 2 with each segment.
- 4. If range is less than threshold
Results
With the same spline used for the brute force example above, but now using the algorithm that uses space partitioning, we can see that this solution performs much less tests. We are drawing a sphere per time we perform a check, the position checked is the center of the sphere.
(The blue numbers on the left represent the number of checks been made for the last few frames, top is current frame)
On top of that, the precision we get by using this method is better, we have reduced drastically the checks and improved the precision. The brute force needed over 150 checks and the biggest number of checks we are getting now is around 20, definitely a win.
Possible Improvements
- Store the position of the initial spheres, we need very little memory to do this and we avoid sampling the curve over the exact same points. Note that we can only do this with the initial spheres as the position of the inner ones depends on the input range distance. Those spheres would be the green ones in the video above.
- In order to improve the precision, once we determine a segment is near enough, we can sample a couple of points along the segment to find a more accurate result. After testing it, we can even perform a binary search and almost never fall in artifacts created by the curvature. This improvement is been used by the video above that shows the precision.
- This is probably the hardest one, try to change the algorithm a bit and make it non-dependent of the _input_range_distance_. An algorithm that does not need this distance would be ideal, still, I think that the improvements that this algorithm provides make the cost of needing this variable worth it.

Nice blog, with plenty of examples. Very easy to understand.
LikeLike